Build scenes. Train AI. Run them anywhere.
OpenFluke is a unified playground for physics scenes, native and web runtimes, and AI behaviors. Design once, deploy to Biocraft (web) or Primecraft (native) with identical JSON assets.
Primecraft Early Access
Explore endless planets with infinite permutations. Push the limits of your device — from onboard AI training to exploring user-generated worlds.
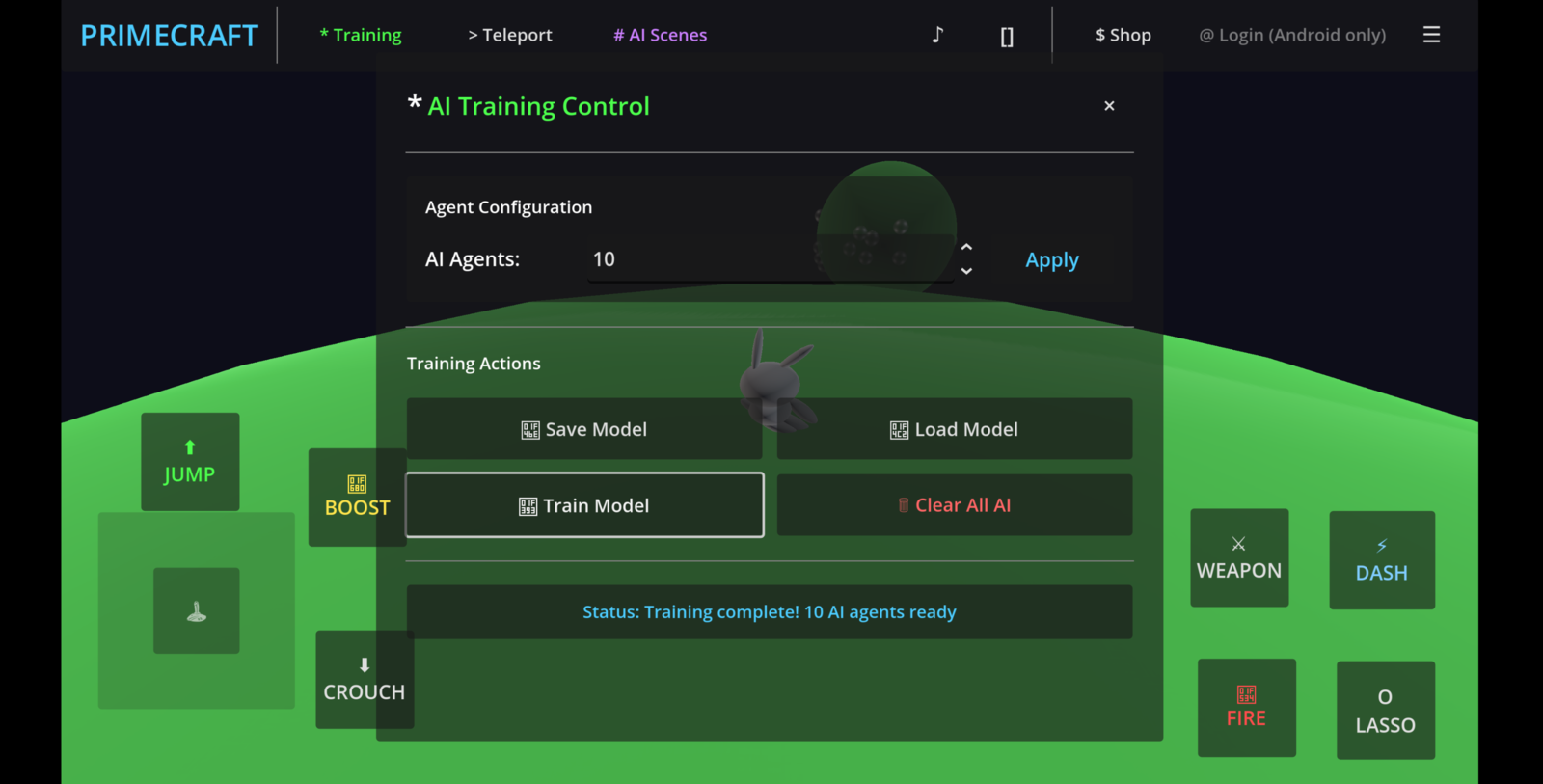
ragdoll-falldown
By @sam
isthisabearordog
By @sam
bear_or_dog
By @sam
reflex-sequence-lets-go-bowl
By @sam
bear-or-dog
By @sam
something_random
By @sam
throw_down
By @sam
playground
By @sam
open-the-gates
By @sam
splat
By @sam
reflex-automation-example
By @sam
Treasure Hunt Explorer: Q-Learning Maze
By @ailearner